排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文)。LTR有三种主要的方法:PointWise,PairWise,ListWise。Ranking SVM算法是PointWise方法的一种,由R. Herbrich等人在2000提出, T. Joachims介绍了一种基于用户Clickthrough数据使用Ranking SVM来进行排序的方法(SIGKDD, 2002)。
1. Ranking SVM的主要思想
Ranking SVM是一种Pointwise的排序算法, 给定查询q, 文档d1>d2>d3(亦即文档d1比文档d2相关, 文档d2比文档d3相关, x1, x2, x3分别是d1, d2, d3的特征)。为了使用机器学习的方法进行排序,我们将排序转化为一个分类问题。我们定义新的训练样本, 令x1-x2, x1-x3, x2-x3为正样本,令x2-x1, x3-x1, x3-x2为负样本, 然后训练一个二分类器(支持向量机)来对这些新的训练样本进行分类,如下图所示:
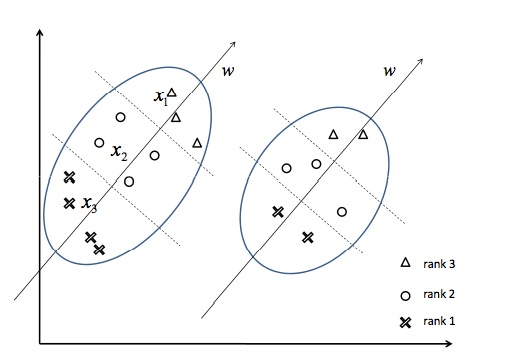
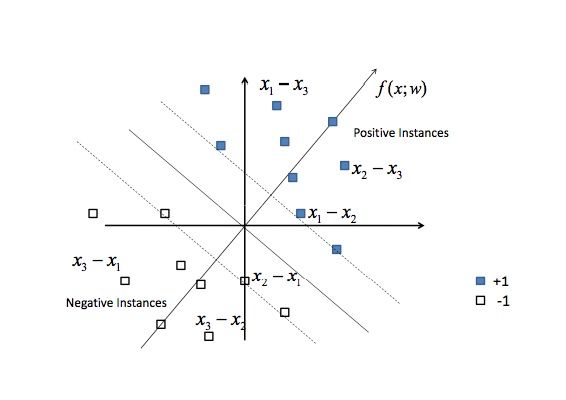
左图中每个椭圆代表一个查询, 椭圆内的点代表那些要计算和该查询的相关度的文档, 三角代表很相关, 圆圈代表一般相关, 叉号代表不相关。我们把左图中的单个的文档转换成右图中的文档对(di, dj), 实心方块代表正样本, 亦即di>dj, 空心方块代表负样本, 亦即di<dj。
2. Ranking SVM
将排序问题转化为分类问题之后, 我们就可以使用常用的机器学习方法解决该问题。 Ranking SVM使用SVM来进行分类:
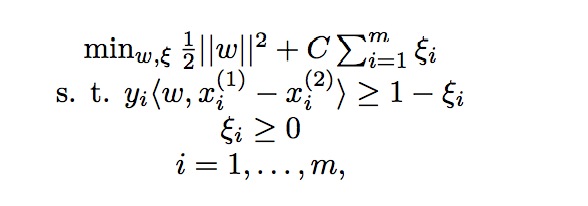
其中w为参数向量, x为文档的特征,y为文档对之间的相对相关性, ξ为松弛变量。
3. 使用Clickthrough数据作为训练数据
T. Joachims提出了一种非常巧妙的方法, 来使用Clickthrough数据作为Ranking SVM的训练数据。
假设给定一个查询"Support Vector Machine", 搜索引擎的返回结果为

其中1, 3, 7三个结果被用户点击过, 其他的则没有。因为返回的结果本身是有序的, 用户更倾向于点击排在前面的结果, 所以用户的点击行为本身是有偏(Bias)的。为了从有偏的点击数据中获得文档的相关信息, 我们认为: 如果一个用户点击了a而没有点击b, 但是b在排序结果中的位置高于a, 则a>b。
所以上面的用户点击行为意味着: 3>2, 7>2, 7>4, 7>5, 7>6。
4. Ranking SVM的开源实现
上有Ranking SVM的开源实现。
数据的格式与LIBSVM的输入格式比较相似, 第一列代表文档的相关性, 值越大代表越相关, 第二列代表查询, 后面的代表特征
3 qid:1 1:1 2:1 3:0 4:0.2 5:0 # 1A2 qid:1 1:0 2:0 3:1 4:0.1 5:1 # 1B 1 qid:1 1:0 2:1 3:0 4:0.4 5:0 # 1C1 qid:1 1:0 2:0 3:1 4:0.3 5:0 # 1D 1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2A 2 qid:2 1:1 2:0 3:1 4:0.4 5:0 # 2B 1 qid:2 1:0 2:0 3:1 4:0.1 5:0 # 2C 1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2D 2 qid:3 1:0 2:0 3:1 4:0.1 5:1 # 3A 3 qid:3 1:1 2:1 3:0 4:0.3 5:0 # 3B 4 qid:3 1:1 2:0 3:0 4:0.4 5:1 # 3C 1 qid:3 1:0 2:1 3:1 4:0.5 5:0 # 3D
训练模型和对测试数据进行排序的代码分别为:
./svm_rank_learn path/to/train path/to/model
./svm_classify path/to/test path/to/model path/to/rank_result
参考文献:
[1]. R. Herbrich, T. Graepel, and K. Obermayer. Large margin rank boundaries for ordinal regression. In Advances in Large Margin Classifiers, 2000.
[2]. T. Joachims. Optimizing Search Engines using Clickthrough Data. SIGKDD, 2002.
[3]. Hang Li. A Short Introduction to Learning to Rank.
[4]. Tie-yan Liu. Learning to Rank for Information Retrieval.
[5].